A minaría de datos ou exploración de datos (a etapa de análise de «knowledge discovery in databases» ou KDD) é un campo da estatística e das ciencias da computación referido aos procesos que tentan descubrir patróns en grandes volumes de conxuntos de datos.[1][2] Emprega métodos de intelixencia artificial, aprendizaxe automática, estatística e sistemas xestores de bases de datos. O obxectivo xeral do proceso de minaría é a extracción de información dun conxunto de datos para a súa transformación posterior nunha estrutura adecuada para analizar e sacar conclusións dos grandes volumes de información.
Ademais da etapa de análise en bruto, a minaría supón xestionar:
Visualización e actualización en liña da información.
O termo é frecuentemente mal utilizado para referirse a calquera forma de datos a gran escala ou procesamiento da información (recolección, extracción, almacenamento, análise e estatísticas). Tamén se emprega con calquera tipo de sistema informático de apoio a decisións, incluíndo a intelixencia artificial, aprendizaxe automática e intelixencia empresarial.
Relación xeral entre os procesos de minado web (web mining) e a minaría de datos.
No uso da palabra, o termo clave é o descubrimento (KDD). Defínese como «detección de algo novo». A miúdo, os termos máis xerais «análises de datos», «análises»; ou, cando se refiren aos métodos actuais, «intelixencia artificial» e «aprendizaxe automática», son máis apropiados para moitos casos que simplemente «minaría de datos».
A tarefa da minaría de datos real é a análise automática ou semiautomática de grandes cantidades de datos coa intención de extraer patróns de interese (descoñecidos en primeira instancia) como:
Grupos de rexistros de datos (análises clúster)
Rexistros pouco usuais (detección de anomalías)
Dependencias (minaría por regras de asociación).
Empréganse técnicas de bases de datos como os índices espaciais. Estes patróns poden ser vistos como unha especie de resumo dos datos de entrada que xogan un papel importante na análise adicional ou, por exemplo, na aprendizaxe automática e análise predictivo.
Ordenación dos datos desordenados para obter coñecemento útil (KDD).
Por exemplo, o procedemento de minaría de datos podería identificar varios grupos nos datos, que logo serían utilizados para obter resultados máis precisos de predición por un sistema de soporte de decisións. Nin a recolección de datos, a preparación de datos, nin a interpretación dos resultados e a información son parte da etapa de minaría de datos, pero é común considerar que pertencen a todo o proceso KDD como pasos adicionais.[3]
Os termos relacionados coa obtención de datos, a pesca de datos e espionaxe dos datos refírense á utilización de métodos de minaría de datos sobre partes pequenas dun conxunto poboacional de grandes dimensións. As inferencias estatísticas destes métodos téñense que mirar con escepticismo, pois están tratando con mostras pequenas. Estes métodos poden, con todo, ser utilizados na creación de novas hipóteses que se proban contra poboacións de datos máis grandes.
As vantaxes da minaría de datos están relacionadas coa capacidade de compartir información e aprender patróns descoñecidos sobre datos "opacos" a primeira vista.
As desvantaxes teñen que ver coa privacidade do minado de datos. Ao facer que a información estea dispoñible, as empresas poden promover problemas de privacidade e seguridade dos seus usuarios. Algunhas solucións suxeridas polos investigadores implican limitar o acceso aos datos, eliminar agrupacións que non son esenciais ou o aumentar o tamaño do dataset para que sexa moito máis difícil extraer conclusións específicas de individuos.[4]
Un proceso típico de minaría de datos consta dos seguintes pasos xerais:
Selección do conxunto de datos (dataset), tanto no que se refire ás variables obxectivo (aquelas coas que se quere traballar: predicir, calcular ou inferir), como ás variables independentes (empregadas para facer o cálculo ou proceso), como posiblemente á mostraxe dos rexistros dispoñibles.
Análise das propiedades dos datos, en especial os histogramas, diagramas de dispersión, presenza de valores atípicos e ausencia de datos (valores nulos NULL).
Transformación do conxunto de datos de entrada, tamén coñecido como preprocesamento dos datos, co obxectivo de preparalos para aplicar técnicas de minaría de datos que se adapten correctamente ao problema. Un problema substancial asociado ao desenvolvemento deste tipo de sistemas cando conteñen texto en inglés é o tamaño do seu vocabulario, que é máis grande que o de calquera outra lingua. Un método que se aplica nestes casos é o de simplificación, previo ao proceso en si, por medio de converter devandito texto a inglés básico; mesmo que contén só 1.000 palabras que tamén se utilizan para describir en notas ao pé o sentido das máis de 30.000 palabras definidas no «Dicionario Básico de Ciencias».[5]Workflow dun proceso de minaría de datos.
Selección e aplicación da técnica de minaría de datos, constrúese o modelo predictivo, de clasificación ou segmentación.
Extracción de coñecemento (Knowledge Discovery), mediante unha técnica de minaría de datos, obtense un modelo de coñecemento, que representa patróns de comportamento observados nos valores das variables do problema ou relacións de asociación entre devanditas variables. Tamén poden usarse varias técnicas á vez para xerar distintos modelos, aínda que xeralmente cada técnica obriga a un preprocesado diferente dos datos.
Interpretación e avaliación de datos. Unha vez obtido o modelo, procédese á súa validación comprobando que as conclusións que lanza son válidas e suficientemente satisfactorias. No caso de obter varios modelos mediante o uso de distintas técnicas, débense comparar os modelos en busca daquel que se axuste mellor ao problema. Se ningún dos modelos alcanza os resultados esperados, debe alterarse algún dos pasos anteriores para xerar novos modelos.
O modelo final pode non superar a avaliación descrita. Nese caso, o proceso poderíase repetirse desde o principio ou a partir de calquera dos pasos anteriores. Esta retroalimentación («feedback») poderase repetir cantas veces sexa necesario até obter un modelo válido.
Unha vez validado o modelo, se resulta aceptable (proporciona saídas axeitadas e/ou con marxes de erro admisibles) este está listo para a súa explotación por parte da organización. Os modelos obtidos por técnicas de minaría de datos aplícanse incorporándoos nos sistemas de análises de información, e mesmo nos sistemas transaccionais. Neste sentido cabe destacar os esforzos do Data Mining Group, que se ocupa de estandarizar a linguaxe PMML (Predictive Model Markup Language), de maneira que os modelos de minaría de datos sexan interoperables en distintas plataformas (datos intercambiados de forma segura e sen perda), con independencia do sistema co que foron construídos. Os principais fabricantes de sistemas de bases de datos e programas de análises da información fan uso do estándar PMML.
Esquema dun almacén de datos (Data Warehouse).
Minaría de datos en almacén, cando as técnicas se aplican sobre información contida en almacéns de datos (Data Warehouse). Grandes organizacións crean e alimentan bases de datos especialmente deseñadas para proxectos de minaría de datos nas que centralizan información potencialmente útil de todas as súas áreas de negocio.
Minaría de datos desestructurados, como información contida en ficheiros de texto dispoñibles en Internet e fontes dispersas.
As cinco fases necesarias dun proxecto de minado de datos son, esencialmente:
Data Mining - The Noun Project.
Comprensióndo negocio e do problema que se quere resolver.
Determinación, obtención e limpeza: dos datos necesarios.
Creación de modelos matemáticos.
Validación, comunicación dos resultados obtidos.
Integración dos resultados nun sistema transaccional ou similar.
A realidade afai ser moito máis complexa que os cinco pasos. Outras metoloxías permiten xestionar a complexidade dun proceso de minaría dunha maneira máis ou menos uniforme.[6]
As técnicas da minaría de datos proveñen da intelixencia artificial e da estatística. Devanditas técnicas non son máis que algoritmos de menor ou maior sofisticación que se aplican sobre un conxunto de datos para obter os resultados.
As técnicas máis representativas son:
Rede neural de varias capas.Redes neuronais.Paradigma de aprendizaxe e procesamento automático inspirado na forma en que funciona o sistema nervioso dos animais. Trátase dun sistema de interconexión de neuronas nunha rede que colabora para producir un estímulo de saída. Algúns exemplos de rede neuronal de emprego común son:
Regresión linear en dúas dimensións.Regresión linear. Dos métodos de aprendizaxe estatística é o máis coñecido e sinxelo de poñer en práctica. É un procedemento rápido e eficaz pero insuficiente en espazos multidimensionais onde poidan relacionarse máis de 2 variables (a solución é a regresión linear multivariante).
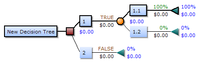
Árbore de decisión.Árbores de decisión. Unha árbore de decisión é un modelo de predición utilizado no ámbito da intelixencia artificial e análise predictiva. Dada unha base de datos constrúense estes diagramas de construcións lóxicas, moi similares aos sistemas de predición baseados en regras, que serven para representar e categorizar unha serie de condicións que suceden de forma sucesiva para resolver un problema. Exemplos:
Modelos estadísticos. Indican os factores que modifican a variable resposta. Empregados en regresión e outras técnicas de aprendizaxe estatística.
Análise clúster ou agrupamento.
Agrupamento ou Clustering. Procedemento de agrupación dunha serie de vectores segundo criterios habitualmente de distancia: os vectores de entrada máis próximos terán características comúns. Exemplos:
Algoritmos supervisados (preditivos): predín un dato (ou un conxunto deles) descoñecido a priori, a partir doutros coñecidos.
Algoritmos non supervisados (ou do descubrimento do coñecemento): descóbrense patróns e tendencias nos datos, o que é a base do propio KDD (Knowledge Discovery in Databases).
A minaría de datos e os procesos de KDD poden percibir os clientes que teñen unha maior probabilidade de responder positivamente a unha determinada oferta, promoción ou acercamento.
As empresas que empregan minaría de datos habitualmente ven o retorno do investimento, pero tamén recoñecen que o número de modelos preditivos desenvolvidos pode crecer moi rapidamente.
En lugar de crear modelos para predicir os clientes que son susceptibles de cambiar, a empresa pode construír modelos separados para cada rexión e/ou tipo de cliente.
Se o obxectivo é determinar cales son os clientes van ser rendibles durante un período de tempo (unha quincena ou un mes, por exemplo), aproximación adecuada sería só enviar ofertas ás persoas que é probable que sexan rendibles.
A automatización dos procesos de minaría é un aspecto fundamental para xestionar todas as versións dun mesmo modelo.
Software de análise interactiva de ventas con Power BI.
Nunha contorna tan cambiante onde os volumes de datos medibles crece exponencialmente grazas á mercadotecnia dixital, «as esperas producidas pola dependencia entre departamentos técnicos e os expertos estadistas conseguen que ao final os resultados das análises sexan inservibles» aos responsables de negocio e toma de decisións.[7][8] Por isto, os provedores de ferramentas de minaría de datos traballan en aplicacións máis fáciles de utilizar no que se coñece como minaría de datos visual. O software Power BI de Microsoft cumpre a función de aplicación de visualización de datos e análise interactiva dos mesos. A demanda de emprego de analista de negocio disparouse a partir do 2010, e as previsión continúan sendo favorables para este tipo de postos de traballo.[9][10]
O exemplo clásico de aplicación da minaría de datos ten que ver coa detección de hábitos de compra en supermercados. A localización dos produtos en locais de alimentación pode estar supeditada ao descubrimento de patróns a través de minaría de datos. As organizacións poden facer uso da información descuberta e incrementar as vendas.
Un exemplo máis habitual é o da detección de patróns de fuga. En moitas industrias —como a banca ou as telecomunicacións— existe un comprensible interese en detectar canto antes aqueles clientes que poidan estar pensando en rescindir os seus contratos para, posiblemente, aceptar mellores ofertas. As minaría de datos axuda a determinar os clientes máis proclives a abandonar a organización mediante comparacións con outros clientes do pasado que tomaron esa acción.
A detección de transaccións de branqueo de capital ou fraude no uso de cartóns de crédito ou servizos de telefonía móbil e, mesmo, na relación dos contribuíntes co fisco, pode predicirse con técnicas de minaría de datos. As operacións fraudulentas adoitan seguir patróns característicos que permiten, con certo grao de probabilidade, distinguilas das lexítimas e desenvolver así mecanismos para tomar medidas rápidas fronte a elas.
A minaría de datos tamén pode ser útil para os departamentos de recursos humanos na identificación das características dos seus empregados de maior éxito. A información obtida pode axudar á contratación de persoal, centrándose nos esforzos dos empregados e os resultados. Ademais, a axuda ofrecida polas aplicacións para dirección estratéxica nunha empresa tradúcense na obtención de vantaxes a nivel corporativo, como:
Xestión de recursos humanos.
Aumento da marxe de beneficios.
Obxectivos compartidos.
Mellores decisións operativas (desenvolvemento de plans de produción ou xestión de man de obra).
Desde comezos da década de 1960 estiveron dispoñibles máquinas oráculo para determinados xogos combinacionais, tamén chamados finais de xogo de taboleiro (por exemplo, para o tres en raia ou en finais de xadrez). Desta forma abriuse unha nova área na minaría de datos que consiste na extracción de estratexias utilizadas por xogadores para aplicalas nas máquinas oráculo.
As formulacións actuais sobre recoñecemento de patróns, non se puideron aplicar con éxito ao funcionamento das máquinas oráculo.
No seu lugar, a produción de patróns perspicaces baséase nunha ampla experimentación con bases de datos sobre eses finais de xogo, combinado cun estudo intensivo dos propios finais de xogo en problemas ben deseñados e con coñecemento da técnica (datos previos sobre o final do xogo en cuestión).
Exemplos notables de investigadores que traballaron neste campo son Berlekamp no xogo de puntos-e-caixas (ou Timbiriche) e John Nunn en finais de xadrez.
As tecnoloxías e os avances con relación á minaría de datos víronse involucrados na industria dos videoxogos. Nela, a necesidade por coñecer aos consumidores e o gusto destes é parte fundamental para o éxito dunha compañía.
Grandes compañías caeron baixo o manto de cancelacións, perdas, fracasos e en casos até a mesma quebra polo mal manexo da información.
Con plataformas de venda centralizada de videoxogos como Steam, as pequenas compañías contrataron os servizos de empresas especializadas no sector da minaría de datos para poder presentar produtos de calidade e publicidade ao público obxectivo ou target do videoxogo.
No estudo da xenética humana, o obxectivo principal é entender a relación entre as partes e a variación individual nas secuencias do ADN humano e a variabilidade na susceptibilidad ás enfermidades.Os cambios na secuencia de ADN dun individuo afectan ao risco de desenvolver enfermidades comúns (por exemplo, o cancro).
Para mellorar o diagnóstico, prevención e tratamento das enfermidades, a minaría de datos aplica técnicas de «redución de dimensionalidade multifactorial».[12]
No ámbito da enxeñaría eléctrica, as técnicas de minaría de datos monitorizan as condicións das instalacións de alta tensión. A finalidade da monitorización é a obtención de información valiosa sobre o estado de illamento dos equipos. Para monitorizar as vibracións e analizar os cambios de carga en transformadores empréganse técnicas de agrupación de datos (clustering) como os mapas auto-organizados (SOM, de Self-Organizing Map). Os SOM detectan concicións anómalas e estiman a natureza das devanditas anomalías.[13]
É común aplicar de técnicas de minaría de datos para a análise de gases disoltos (DGA, de Dissolved Gas Analysis) en transformadores eléctricos. A análise de gases disoltos funciona como ferramenta para diagnosticar transformadores. Os mapas auto-organizados (SOM) utilízanse para analizar datos e determinar tendencias que poderían pasarse por alto utilizando as técnicas clásicas (DGA).
Na minaría de datos destacan técnicas de aprendizaxe estatística como:
Análise da varianza: avalía a existencia de diferenzas significativas entre as medias dunha ou máis variables continuas en poboacións distintas.
Regresión: define a relación entre unha ou máis variables.
Proba chi-cadrado: realiza o contraste da hipótese de dependencia entre variables.
Exemplo de agrupamento ou clustering dos datos en dos grupos principais.Análise de agrupamento ou clustering: permite a clasificación dunha poboación de individuos caracterizados por múltiples atributos (binarios, cualitativos ou cuantitativos) nun número determinado de grupos, con base nas semellanzas ou diferenzas dos individuos.
Análise discriminante: permite a clasificación de individuos en grupos previamente establecidos (aprendizaxe supervisada), e permite atopar a regra de clasificación dos elementos destes grupos.
Series de tempo: permiten o estudo da evolución dunha variable a través do tempo para poder realizar predicións a partir dese coñecemento e baixo o suposto de que non se produzan cambios estructurais.
Algoritmos xenéticos: métodos numéricos de optimización, nos que aquela variable ou variables que se pretenden optimizar xunto coas variables de estudo constitúen un segmento de información. Aquelas configuracións das variables de análises que obteñan mellores valores para a variable de resposta corresponderán a segmentos con maior capacidade reprodutiva. A través da reprodución, os mellores segmentos perduran e a súa proporción crece de xeración en xeración. Pódense introducir elementos aleatorios para a modificación das variables (mutacións). Ao cabo de certo número de iteracións, a poboación estará constituída por boas solucións ao problema de optimización, pois as malas solucións foron descartándose iteración tras iteración.
Intelixencia artificial: un modelo intelixente de tipo LLM (Large Language Model) pode interpretar os datos dispoñibles.
Sistemas Expertos: emprego de regras prácticas extraídas do coñecemento de expertos nun dominio. A base son inferencias ou situacións de causa-efecto.
Sistemas Intelixentes: similares aos sistemas expertos, pero con maior vantaxe ante novas situacións descoñecidas (ás que nunca se enfrontou antes o experto).
Redes neuronais: métodos de proceso numérico en paralelo. Neles, as variables interactúan mediante transformacións (lineais ou non lineais) até obter unhas saídas. A comparación das predicións e das saídas reais mediante unha función de perda inicia un proceso de retroalimentación, co cal a rede se reconfigura iterativamente até obter un modelo axeitado.
A minaría de datos orixinouse como tal nos anos sesenta, e nos primeiros días do campo os científicos non se preocuparon demasiado pola falta de datos e información necesaria para conseguir o resultado esperado da aplicación ou negocio. As desvantaxes eran as seguintes:
Falta de coñecemento que aplicar ao negocio para obter beneficio.
Explotación incompleta da información dispoñible nos datos de entrada.
A práctica máis común era construír modelos con parámetros distintos ata empregar o que mellores resultados conseguise. Mais o enfoque da minaría de datos foi cambiando ata pasar a ser unha ciencia e non unha arte.
En 1948 Claude Shannon publicou un traballo chamado «Unha teoría matemática da comunicación». O concepto derivou na denominada teoría da información e sentou as bases da comunicación e da codificación dos datos. A teoría de Shannon propuxo unha maneira de medir a cantidade de información a ser expresada en bits. [14]
En 1999, Dorian Pyle publicou o seu libro «Data Preparation for Data Mining».[15] Nel propón unha maneira de usar a teoría da información de Shannon para analizar datos. Neste novo enfoque, unha base de datos é unha canle que transmite información.
Por unha banda está o mundo real, que captura datos xerados polo negocio.
Polo outro están todas as situacións e problemas importantes do negocio.
De acordo a Dorian Pyle, a información flúe desde o mundo real (a través dos datos) até a problemática do negocio ou organización.
Coa perspectiva da teoría da información, é posible medir a cantidade de información dispoñible nos datos e que porción da mesma poderá utilizarse para resolver a problemática do negocio. Exemplo práctico:
Os datos conteñen un 65% da información necesaria para predicir que cliente rescindirá os seus contratos.
O modelo final é capaz de facer predicións cun 60 % de acerto.
Nese caso, pódese asegurar que a ferramenta que xerou o modelo fixo un bo traballo capturando a información dispoñible.
Agora, si o modelo tivese unha porcentaxe de acertos de só o 10 %, por exemplo, entón tentar outros modelos podería ser unha mellor solución.
A minaría de datos é especialmente sensible a transformacións e cambios tecnolóxicos, novas estratexias de mercadotecnia, modelos de compra en liña, etc.
Os datos non estruturados (texto, páxinas de Internet), adquiriron maior importancia segundo crecía o volume de datos que se recompilaban na nube.
Os algoritmos e resultados obtidos en sistemas operacionais e portais de Internet necesitaban ser incorporados.
Os novos procesos teñen a necesidade de funcionar en tempo real, practicamente en liña (por exemplo, en casos de fraude cun cartón de crédito).
Os tempos de resposta crecen debido ao gran volume de datos. Os problemas que requiren de resposta en tempo real (movementos bancarios) atopan difícil apoiarse en modelos moi complexos que procesen datos durante unha cantidade de tempo inasumible.


.png)




_-_The_Noun_Project.svg)